
Concepts You Have to Know for Data Science Interviews — Part III. Basic Supervised Learning Models
Most frequently asked questions in data scientist interviews for modeling


Most frequently asked questions in data scientist interviews for modeling
This is the 3rd article in my interview series. I’m hoping this series will function as a centralized starting point for aspiring data scientists in terms of interview preparation. The first two articles are here if you are interested:
Concepts You Have to Know for Data Science Interviews — Part I: Distribution
Concepts You Have to Know for Data Science Interviews — Part II. Probability
In this article, I want to talk about arguably the most interesting part for a lot of aspiring data scientists — ML. ML is a super complicated topic, so I won’t even attempt to cover EVERYTHING about it in one post. In fact, I will separate the ML part into several posts and talk about different aspects of ML and different categories of models in each of them. In this post, I will focus only on the basic supervised learning models.
There are countless types of models out there when it comes to ML, from simple models like linear and logistic regression all the way to convoluted ones like deep learning and reinforcement learning. I will post by post cover the important ones that will show up in interviews.
First things first, it’s important to know that unless you are targeting super modeling-intensive roles such as machine learning engineer (MLE) or research scientists, ML usually is NOT the biggest focus for interviews. The interviewers usually ONLY want to see that you have a basic level of understanding of different models and modeling techniques; you WON’T be asked to whiteboard proofs or defend the choice for the number of layers in a neural network you built.
In general, ML models/techniques can be separated into two categories— Supervised vs. unsupervised learning.
The difference between supervised and unsupervised learning is one of the most fundamental concepts data scientists should be familiar with. Supervised learning is the general category of all the ML techniques that utilizes labeled datasets, whereas unsupervised learning techniques work with unlabeled datasets. A concrete example: If you want to build a model to distinguish dogs from cats, you would be using supervised learning because there should be a clearly correct answer to each data point whether it is a dog or a cat (the categories you want to predict). Whereas if you just want to cluster house pets together, you would use unsupervised learning. There’s not a clearly “correct” answer for each data point’s label — a small dog may be grouped into the same group as other small cats instead of big dogs. This article will focus on most commonly tested supervised learning techniques; I will go into more advanced supervised learning models and unsupervised learning in the following articles.
Linear regression
This is arguably the most rudimentary model used in ML (if you think it “counts” as ML). Linear regression is the most common method of supervised learning that’s most suitable to predict a continuous variable (as opposed to categorical variables).
Linear regression essentially is trying to fit the best line through all training data points. The definition of “the best line” varies depending on the choice of the loss function. The most commonly used one is “ordinary least squares (OLS)”, which finds the best line by minimizing the sum of squared errors. The error is defined as rᵢ = yᵢ -y^, where y^ is the predicted value by the model and yᵢ is the observed (true) value. The value you want to minimize is the sum of the aforementioned error terms
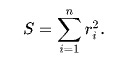

{kind=link}
Logistic regression
The biggest difference between logistic regression and linear regression is that while linear regression models a continuous variable, logistic regression models the probability of an event (an event with binary outcomes), hence the output is between 0 and 1.
It’s worth noting that, even though commonly used for classification, the logistic regression itself is NOT a classifier. But it can be turned into a classifier when layered with a threshold on top (usually 0.5). With a cutoff determined, the probability can be turned into a binary output. As an example, if you are trying to predict whether an e-mail is spam or not, a logistic regression with a threshold of 0.5 would classify any e-mail with a predicted “probability of being spam” ≥ 50% as spam.
Understanding that the classifier consists of two parts — a threshold and the logistic regression — can help you understand why choosing a proper cutoff is an essential but usually overlooked part of model tuning when it comes to classifiers powered by logistic regression.
CART
CART is short for categorization and regression trees; as the name suggest, it is a supervised learning technique that can be used to predict categorical or continuous variables. CART is usually talked about together with Random Forest, because CART is the simpler version; it’s a single tree instead of, well, a forest (I will cover Random Forest in the next article).
CART’s biggest advantage when compared to regressions, or even random forest, is its interpretability, because it’s possible to plot the feature split used to build the tree. The illustration below showcases a super simple CART model. Illustrations like this can be easily plotted by most CART packages you use to fit the model and it can help you visualize how the model is built in the background. Another neat thing is that it shows you what features were used first to split the model; so it also illustrates feature importance.
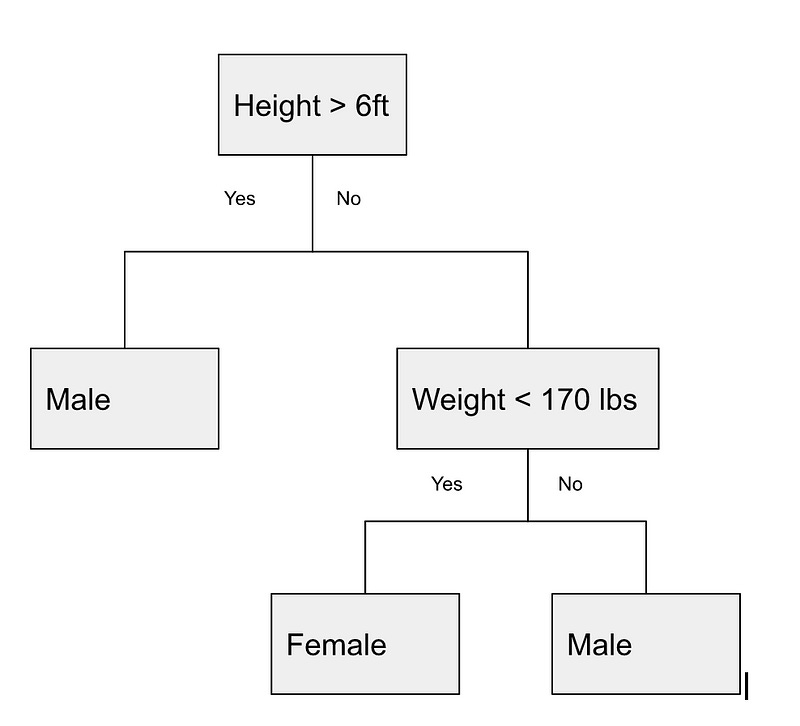
How are these tested and what to watch out for
In general, there are two approaches to test these fundamental ML modeling concepts — resume-driven or theory-driven.
Resume-driven: the interview questions will be based on your resume. So make sure you take a couple of hours to take a trip down memory lane and refresh your understanding of the modeling experiences you mention in your resume. Depending on the interviewer and his/her background in machine learning, they might ask in-depth questions about certain algorithms you mention.
Theory-driven: If you lack modeling experience, or modeling shows up in a case study portion of the interview, the questions will be theoretical and hypothetical. The interviewers will ask you what you WOULD DO in a certain situation. And they might throw you a curve ball by planting some problems with the dataset and see if you know how to deal with difficult data problems in modeling (we will cover that in detail in my upcoming article talking about model training).
Things to remember: When talking about your modeling experience, make sure you showcase that you understand interpretability is the most important thing when building a model. There are countless ways to visualize model performance and feature importance for almost every commonly-used model. Stay tuned for an article on that too. Another thing to remember is that data cleaning and feature engineering are as important, if not more so than the modeling itself. Otherwise your model will suffer from the infamous “garbage in garbage out” symptom.
Interested in reading more about data science career tips? I might have something for you:
5 Lessons McKinsey Taught Me That Will Make You a Better Data Scientist
towardsdatascience.com
Why I Left McKinsey as a Data Scientist
Things you should consider before starting as a data science consultanttowardsdatascience.com