
This tutorial will make your API data pull so much easier
An easy but comprehensive guide to automate API data pull with Python

Hands-on Tutorials
An easy but comprehensive guide to automating API data pulls with Python
Motivation
Every good analysis starts with good data. This data can come from any number of sources; if you are a Data Analytics professional, much of the data you are working with will likely come from your employer’s internal products and systems. However, in all likelihood, at some point you will find yourself wanting to enrich your analysis by pulling in a third party’s data.
Many companies and organizations offer their data through an Application Programming Interface (API): weather data, stock prices, Google Maps data, crime statistics, you name it. APIs allow developers and end users to access this data in a secure and standardized way, and by following the instructions in the API documentation, you can pull data without the need for much coding knowledge.
So far, so good, right? That’s what I thought, until I needed to access API data for a recent project at work. I quickly discovered that there is a record limit for each API call, and in order to get all the data I wanted, I would need 1095 separate API calls. Yeah… I’m not going to do that manually.
My first thought was to look online (Stackoverflow, Medium, etc.) for existing solutions to automate API data pulls with Python, but I couldn’t find any end-to-end guide that provided an adaptable solution for my situation. After spending an evening figuring it out myself, I decided to document my easy yet comprehensive solution for automating this process for my future self and anyone who is interested in attempting something similar. I will be demonstrating the process with TMDB’s API.
A little introduction for TMDB’s API: TMDB is a site that provides a free API portal for researchers who are interested in getting access to movie data. It is free to register for an account and get a free personal API key (an API key is a crucial piece of information for accessing any API portal, think about it like a digital ticket for an event). For the purpose of this demonstration, assume your API key is “1a2b3c4d5e”.
Furthermore, for this example, let’s assume we are trying to find out whether each movie in a list belongs to a collection (i.e. whether it’s considered a sequel) by querying the TMDB API.
Step 1: Understand the API data query and what it returns
Before accessing an API, the first step is to read the API documentation; this step is crucial because in order to know what data to pull, how to pull it and how to unpack it, you need some understanding of the API and how it is structured. The link to the TMDB API general documentation can be found here; I would usually budget 0.5–2 hours just to read through and understand how the API works and how to set up different queries for different things. Depending on how complicated the API is, it can be difficult to find out which part of the API service you should use to pull the relevant data.
In order to find out whether a movie belongs to a collection using the TMDB API, we need to use the “get movie detail” query to pull the movie detail for each movie. The documentation usually indicates the parameters you need to provide for the query and the format of the query result (as seen below):
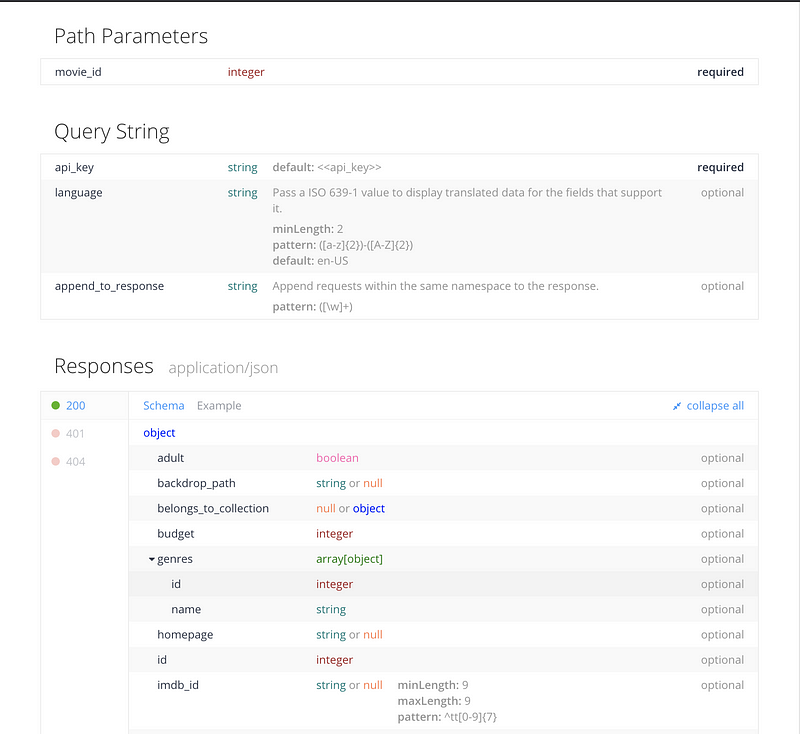
The documentation should also give you an example of how the query looks like and where to fill in the parameters requested (shown below). We will put this into practice with a test query in the next step.
https://api.themoviedb.org/3/movie/{movie_id}?api_key=<<api_key>>&language=en-USStep 2: Understand how to unpack the return from API
Always, always, always try to pull a small sample first so it’s easier to visualize the output and understand it. By substituting “API key” below with your API key (“1a2b3c4d5e” for demo purposes) and providing a movie id of interest (using “464052”, Wonder Woman 1984, as an example here), we can form an API query like this:
https://api.themoviedb.org/3/movie/464052?api_key=1a2b3c4d5e&language=en-USand we get back the result for the movie as shown below:

Okay, that is a pretty ugly format that most people (including me) don’t know how to deal with; unfortunately JSON is the format most API portals return their data in, so we need a way to extract the data we need from this jiberish and put it in a format we can easily digest as humans (say CSV). If you stare at the results above for long enough, you will be able to see that it is essentially a similar format as a Python dictionary (beautified results shown below).
{
"adult": false,
"backdrop_path": "/srYya1ZlI97Au4jUYAktDe3avyA.jpg",
"belongs_to_collection": {
"id": 468552,
"name": "Wonder Woman Collection",
"poster_path": "/8AQRfTuTHeFTddZN4IUAqprN8Od.jpg",
"backdrop_path": "/n9KlvCOBFDmSyw3BgNrkUkxMFva.jpg"
},
"budget": 200000000,
"genres": [
{
"id": 14,
"name": "Fantasy"
},
{
"id": 28,
"name": "Action"
},
{
"id": 12,
"name": "Adventure"
}
],
"homepage": "https://www.warnerbros.com/movies/wonder-woman-1984",
"id": 464052,
"imdb_id": "tt7126948",
"original_language": "en",
"original_title": "Wonder Woman 1984",
"overview": "Wonder Woman comes into conflict with the Soviet Union during the Cold War in the 1980s and finds a formidable foe by the name of the Cheetah.",
"popularity": 7842.973,
"poster_path": "/8UlWHLMpgZm9bx6QYh0NFoq67TZ.jpg",
"production_companies": [
{
"id": 9993,
"logo_path": "/2Tc1P3Ac8M479naPp1kYT3izLS5.png",
"name": "DC Entertainment",
"origin_country": "US"
},
{
"id": 174,
"logo_path": "/ky0xOc5OrhzkZ1N6KyUxacfQsCk.png",
"name": "Warner Bros. Pictures",
"origin_country": "US"
},
{
"id": 114152,
"logo_path": null,
"name": "The Stone Quarry",
"origin_country": "US"
},
{
"id": 128064,
"logo_path": "/13F3Jf7EFAcREU0xzZqJnVnyGXu.png",
"name": "DC Films",
"origin_country": "US"
},
{
"id": 507,
"logo_path": "/z7H707qUWigbjHnJDMfj6QITEpb.png",
"name": "Atlas Entertainment",
"origin_country": "US"
},
{
"id": 429,
"logo_path": "/2Tc1P3Ac8M479naPp1kYT3izLS5.png",
"name": "DC Comics",
"origin_country": "US"
}
],
"production_countries": [
{
"iso_3166_1": "US",
"name": "United States of America"
}
],
"release_date": "2020-12-16",
"revenue": 85400000,
"runtime": 151,
"spoken_languages": [
{
"english_name": "English",
"iso_639_1": "en",
"name": "English"
}
],
"status": "Released",
"tagline": "A new era of wonder begins.",
"title": "Wonder Woman 1984",
"video": false,
"vote_average": 7.3,
"vote_count": 1928
}All JSON returns from API portals can be treated as a dictionary when used in Python. If you are familiar with Python, you can see that the “collection” information can easily be unpacked by accessing the “belongs_to_collection” element from the dictionary above.
Step 3: How to pull everything together automatically with Python
As you can see, you can only provide one movie ID in each query, so if you want to get the “collection” information for 1000 movies, you have to change the movie ID in the query, run the query, and then copy out and combine the relevant information 1000 times! So here comes the most important question, how do we get all the steps aforementioned into Python and automate the process of pulling (only) the collection information for movies we are interested in?
Let’s start by important all the packages that we need.
#let's import all the packages we need
#requests: package used to query API and get the result back in Python
#json: package used to read and convert JSON format
#csv: package used to read and write csvimport requests,json,csv,osNext, use the requests package to query the API (trying to get the same result as Step 2); this step will return the result in JSON format.
#document all the parameters as variables
API_key = '1a2b3c4d5e'
Movie_ID = '464052'#write a function to compose the query using the parameters provideddef get_data(API_key, Movie_ID):
query = 'https://api.themoviedb.org/3/movie/'+Movie_ID+'?
api_key='+API_key+'&language=en-US'
response = requests.get(query)
if response.status_code==200:
#status code ==200 indicates the API query was successful
array = response.json()
text = json.dumps(array)
return (text)
else:
return ("error")The last step is to unpack the result and write it to a CSV file:
def write_file(filename, text):
dataset = json.loads(text)
csvFile = open(filename,'a')
csvwriter = csv.writer(csvFile)
#unpack the result to access the "collection name" element
try:
collection_name = dataset['belongs_to_collection']['name']
except:
#for movies that don't belong to a collection, assign null
collection_name = None
result = [dataset['original_title'],collection_name]
# write data
csvwriter.writerow(result)
print (result)
csvFile.close()Pulling the functions together, for demonstration purposes, we have two movies in the list we want to pull data for:
movie_list = ['464052','508442']
#write header to the file
csvFile = open('movie_collection_data.csv','a')
csvwriter = csv.writer(csvFile)
csvwriter.writerow(['Movie_name','Collection_name'])
csvFile.close()for movie in movie_list:
text = get_data(API_key, movie)
#make sure your process breaks when the pull was not successful
#it's easier to debug this way
if text == "error":
break
write_file('movie_collection_data.csv', text)And a beautiful CSV file like the one below will emerge from all the chaotic JSON data you pulled from the API!

That’s it! Hopefully repeated manual API pulls will now only be a faint, traumatic memory.